 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMedBench: Towards Medical AutoResearch with Agentic AI Models
Jun 01, 2026Autonomous agents are increasingly expected to support end-to-end medical-AI research workflows, moving beyond isolated prediction tasks or short-form clinical question answering. However, existing medical agent benchmarks primarily evaluate final outputs, providing limited visibility into agent behavior within the research process. To address this gap, we present AutoMedBench, a workflow-aware benchmark for autonomous medical-AI research across diverse medical imaging and multimodal inference tasks, organizing agent execution into a unified five-stage workflow (S1-S5): Plan, Setup, Validate, Inference, and Submit. It comprises long-horizon tasks with each run averaging 33 agent turns, spanning five research tracks: segmentation, image enhancement, visual question answering (VQA), report generation, and lesion detection. Each task is evaluated under two difficulty tiers, Lite and Standard, which use the same data and metrics but differ in the amount of task-brief scaffolding, and each run is scored using both final task performance and S1-S5 stage scores, enabling stage-level analysis from the initial task brief to the final submitted artifact. Across thousands of recorded runs, stage-level scoring reveals that Validate is the weakest workflow stage on average, whereas Setup is the strongest, suggesting that current agents are better at making pipelines executable than at verifying their reliability. Post-run error analysis further shows that verification and submission failures dominate tagged errors, accounting for 37.7% and 38.1% of fired codes respectively, whereas task-understanding errors are rare at 0.9%, and runs with one fired error code have a 48% lower overall score than runs with no error code on average.
CmIVTP: Cross-modal Interaction-based Vessel Trajectory Prediction for Maritime Intelligence
May 26, 2026Maritime intelligent transportation systems (MITS) are essential for ensuring navigation safety and efficiency in busy waterways. However, accurate vessel trajectory prediction remains challenging due to the limitations of single-source data. Automatic identification system (AIS) data is often sparse or unavailable for small vessels, while closed-circuit television (CCTV) data alone cannot fully capture dynamic vessel behavior. To mitigate these challenges, we propose a cross-modal interaction-based vessel trajectory prediction (named CmIVTP) framework to model the intricate interactions between vessel dynamics and environmental constraints. Specifically, we introduce a target-aware scene encoder to extract scene semantic features, effectively capturing vessel-environment interactions and enhancing trajectory prediction accuracy. In addition, we propose a cross-modal interaction transformer, which integrates AIS-derived motion features, CCTV-based environmental features, and scene representations. It leverages cross-modal attention mechanisms to simultaneously capture intra-modal semantics and inter-modal interactions, ensuring dynamically consistent and environmentally feasible predictions. Furthermore, we construct a vessel group trajectory bank by clustering historical AIS trajectories into representative motion patterns, providing an efficient and scalable approach for candidate trajectory generation. Additionally, we introduce the maritime multimodal dataset plus (named Maritime-MmD$^+$), a large-scale dataset that synchronizes AIS data and CCTV video data, providing robust support for multimodal trajectory prediction research. Extensive experiments demonstrate that CmIVTP achieves better performance on multimodal-driven vessel trajectory prediction benchmarks. The code resources for this work can be available at https://github.com/LouisYxLu/CmIVTP.
Kinetic-Optimal Scheduling with Moment Correction for Metric-Induced Discrete Flow Matching in Zero-Shot Text-to-Speech
May 10, 2026Metric-induced discrete flow matching (MI-DFM) exploits token-latent geometry for discrete generation, but its practical use is limited by two issues: heuristic schedulers requiring hyperparameter search, and finite-step path-tracking error from its first-order continuous-time Markov chain (CTMC) solver. We address both issues. First, we derive a kinetic-optimal scheduler for prescribed scalar-parameterized probability paths, and instantiate it for MI-DFM as a training-free numerical schedule that traverses the path at constant Fisher-Rao speed. Second, we introduce a finite-step moment correction that adjusts the jump probability while preserving the CTMC jump destination distribution. We validate the resulting method, GibbsTTS, on codec-based zero-shot text-to-speech (TTS). Under controlled comparisons with a unified architecture and large-scale dataset, GibbsTTS achieves the best objective naturalness and is preferred in subjective evaluations over masked discrete generative baselines. Additionally, in comparison with the evaluated state-of-the-art TTS systems, GibbsTTS shows strong speaker similarity, achieving the highest similarity on three of four test sets and ranking second on the fourth. Project page: https://ydqmkkx.github.io/GibbsTTSProject
Surg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
LUMEN: Longitudinal Multi-Modal Radiology Model for Prognosis and Diagnosis
Feb 24, 2026Large vision-language models (VLMs) have evolved from general-purpose applications to specialized use cases such as in the clinical domain, demonstrating potential for decision support in radiology. One promising application is assisting radiologists in decision-making by the analysis of radiology imaging data such as chest X-rays (CXR) via a visual and natural language question-answering (VQA) interface. When longitudinal imaging is available, radiologists analyze temporal changes, which are essential for accurate diagnosis and prognosis. The manual longitudinal analysis is a time-consuming process, motivating the development of a training framework that can provide prognostic capabilities. We introduce a novel training framework LUMEN, that is optimized for longitudinal CXR interpretation, leveraging multi-image and multi-task instruction fine-tuning to enhance prognostic and diagnostic performance. We conduct experiments on the publicly available MIMIC-CXR and its associated Medical-Diff-VQA datasets. We further formulate and construct a novel instruction-following dataset incorporating longitudinal studies, enabling the development of a prognostic VQA task. Our method demonstrates significant improvements over baseline models in diagnostic VQA tasks, and more importantly, shows promising potential for prognostic capabilities. These results underscore the value of well-designed, instruction-tuned VLMs in enabling more accurate and clinically meaningful radiological interpretation of longitudinal radiological imaging data.
Improved Evidence Extraction for Document Inconsistency Detection with LLMs
Jan 06, 2026Large language models (LLMs) are becoming useful in many domains due to their impressive abilities that arise from large training datasets and large model sizes. However, research on LLM-based approaches to document inconsistency detection is relatively limited. There are two key aspects of document inconsistency detection: (i) classification of whether there exists any inconsistency, and (ii) providing evidence of the inconsistent sentences. We focus on the latter, and introduce new comprehensive evidence-extraction metrics and a redact-and-retry framework with constrained filtering that substantially improves LLM-based document inconsistency detection over direct prompting. We back our claims with promising experimental results.
Better Tokens for Better 3D: Advancing Vision-Language Modeling in 3D Medical Imaging
Oct 23, 2025Recent progress in vision-language modeling for 3D medical imaging has been fueled by large-scale computed tomography (CT) corpora with paired free-text reports, stronger architectures, and powerful pretrained models. This has enabled applications such as automated report generation and text-conditioned 3D image synthesis. Yet, current approaches struggle with high-resolution, long-sequence volumes: contrastive pretraining often yields vision encoders that are misaligned with clinical language, and slice-wise tokenization blurs fine anatomy, reducing diagnostic performance on downstream tasks. We introduce BTB3D (Better Tokens for Better 3D), a causal convolutional encoder-decoder that unifies 2D and 3D training and inference while producing compact, frequency-aware volumetric tokens. A three-stage training curriculum enables (i) local reconstruction, (ii) overlapping-window tiling, and (iii) long-context decoder refinement, during which the model learns from short slice excerpts yet generalizes to scans exceeding 300 slices without additional memory overhead. BTB3D sets a new state-of-the-art on two key tasks: it improves BLEU scores and increases clinical F1 by 40% over CT2Rep, CT-CHAT, and Merlin for report generation; and it reduces FID by 75% and halves FVD compared to GenerateCT and MedSyn for text-to-CT synthesis, producing anatomically consistent 512*512*241 volumes. These results confirm that precise three-dimensional tokenization, rather than larger language backbones alone, is essential for scalable vision-language modeling in 3D medical imaging. The codebase is available at: https://github.com/ibrahimethemhamamci/BTB3D
Exploring Task Performance with Interpretable Models via Sparse Auto-Encoders
Jul 08, 2025



Large Language Models (LLMs) are traditionally viewed as black-box algorithms, therefore reducing trustworthiness and obscuring potential approaches to increasing performance on downstream tasks. In this work, we apply an effective LLM decomposition method using a dictionary-learning approach with sparse autoencoders. This helps extract monosemantic features from polysemantic LLM neurons. Remarkably, our work identifies model-internal misunderstanding, allowing the automatic reformulation of the prompts with additional annotations to improve the interpretation by LLMs. Moreover, this approach demonstrates a significant performance improvement in downstream tasks, such as mathematical reasoning and metaphor detection.
Flexible and Efficient Drift Detection without Labels
Jun 10, 2025



Machine learning models are being increasingly used to automate decisions in almost every domain, and ensuring the performance of these models is crucial for ensuring high quality machine learning enabled services. Ensuring concept drift is detected early is thus of the highest importance. A lot of research on concept drift has focused on the supervised case that assumes the true labels of supervised tasks are available immediately after making predictions. Controlling for false positives while monitoring the performance of predictive models used to make inference from extremely large datasets periodically, where the true labels are not instantly available, becomes extremely challenging. We propose a flexible and efficient concept drift detection algorithm that uses classical statistical process control in a label-less setting to accurately detect concept drifts. We shown empirically that under computational constraints, our approach has better statistical power than previous known methods. Furthermore, we introduce a new drift detection framework to model the scenario of detecting drift (without labels) given prior detections, and show our how our drift detection algorithm can be incorporated effectively into this framework. We demonstrate promising performance via numerical simulations.
Improved LLM Agents for Financial Document Question Answering
Jun 10, 2025
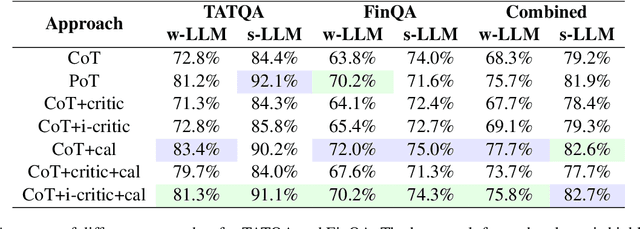
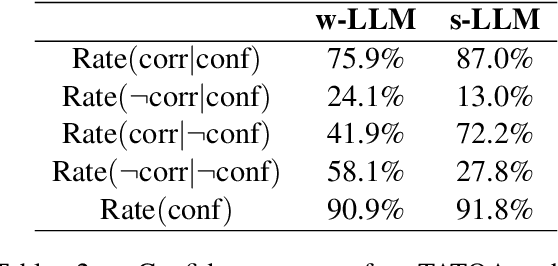
Large language models (LLMs) have shown impressive capabilities on numerous natural language processing tasks. However, LLMs still struggle with numerical question answering for financial documents that include tabular and textual data. Recent works have showed the effectiveness of critic agents (i.e., self-correction) for this task given oracle labels. Building upon this framework, this paper examines the effectiveness of the traditional critic agent when oracle labels are not available, and show, through experiments, that this critic agent's performance deteriorates in this scenario. With this in mind, we present an improved critic agent, along with the calculator agent which outperforms the previous state-of-the-art approach (program-of-thought) and is safer. Furthermore, we investigate how our agents interact with each other, and how this interaction affects their performance.